Vous avez publié un feed avec skyfeed.app mais vous ne savez pas comment le supprimer ? 📌
Suivez ce tuto : Comment supprimer un custom feed ?
Une contribution de @leandraa.fr
Comment épingler un post dans un Feed ? c’est par ici 📌
Nouveau : comment utiliser les mots de passe d’application (app passwords) avec les différents outils et applications pour Bluesky ? c’est par ici 📌
Une contribution de @mwyann.fr
Création du feed de La Chute, comment cuisiner un Feed avec une liste approuvée, une liste pour les trolls et des mots clefs pour le public ? c’est par ici 📍📌
Comment créer un Custom Feed combiné ? c-a-d, contenant des posts du réseaux avec mot-clef et en même temps des posts d’un compte spécifique basé sur un critère, ici un nom de domaine ? lien vers le tutoriel.
Avec les conseils aimables de @leandraa.fr et @mwyann.fr
Comment utiliser son propre nom de domaine sur Bluesky? Video 📌
Ce soir, 19h (heure 🇧🇪) on se fait un petit question & réponses à propos de Bluesky, en direct sur la chaîne youtube de @rmendes.net 📹
Lien du direct
-
il n’y a pas de questions bêtes
-
c’est format tranquille en mode test
[Tech] comment déployer son propre “générateur de feed” sur son propre domaine, sans dépendre de @skyfeed.app ou de @goodfeeds.co ?
Une des approches est très bien détaillée ici
Comment créer un Custom Feed pour y ranger des posts à ne pas oublier, bref des signets ? 📌
Tuto
- votre DID
- un mot clef qui va vous servir de filtre
- Skyfeed.app
- 2 min de votre temps
Vous commencez par créer un nouveau custom feed sur skyfeed.app, à côté de ça, dans le bloc Input vous choisissez Single User et vous cliquez Select Yourself
Puis vous ajoutez un regex bloc avec la requête
📌📍Si votre émoji est précédé comme ceci : ^📌 ou comme cela 📍$
ça va faire le filtre, le match en fonction du fait que l’émoji est au debut du post ou à la fin du post.
tandis que 📌 ou📍tou simple, précise que l’émoji est n’importe où dans le post.
Ne prenez pas tout, choisissez un cas de figure et ensuite utiliser ce format lorsque vous composez vos post et que vous voulez le garder en signet.
Perso j’utilise 📌 pour les tutos et j’utilise 📍 dans le bloc regex pour les astuces, résultat j’ai deux custom feed qui stock ces deux types de posts et je n’ai plus à y penser, j’ai facile à retrouver mes posts de l’un ou l’autre format/type de signet.
crédit à @mwyann.fr pour cette astuce !
Évidemment, cette idée peut être appliquée pour n’importe quoi d’autre en changeant les émojis filtres au besoin.
Résultats
ps: en activant le cas sur les reposts, ça vous permet de simplement reposter le post d’un ami, en ajoutant 📌 ou📍pour que son post soit rangé dans vos signets.

Comment déployer un news bot RSS sur Bluesky?
pré-requis
- un compte bluesky dédié
- un “app password”
- un flux RSS source de contenu à publier
- bsky.rss
- la commande git installée
- Docker et Docker-Compose installé

Pour l’exercice, on va déployer un newsbot https://disclose.ngo/ C’est un média d’investigation.
Setup
Pas besoin d’un gros serveurs, il suffit d’avoir un ordinateur, évidemment si vous le débranché, le bot s’éteint aussi, donc, c’est plus pratique de mettre ça en ligne, sur un petit vps, même un serveur à 5€ par mois fera tout à fait l’affaire.
Et sinon, votre machine, que ce soit sur Windows, Linux ou macOS, tout est bon !
un compte bluesky dédié
- Résultat de ce tuto visible sur ce bot : (sans les images parce que le site à la source ne support pas bien la technologie OpenGraph)
- disclosengo.bsky.social
un “app password”
- gardez-le au chaud pour plus tard
un flux RSS source du contenu à publier
le site Disclose.ngo est un site sur mesure, mais il propose 2 flux RSS
- Flux en Anglais : https://disclose.ngo/feed?lang=en
- Flux en Français : https://disclose.ngo/feed
Pour trouver le flux RSS d’un site source, l’extension Feedbro est très utile on pourrait faire tout un article sur cette question, mais en général, il y a toujours moyen de récupérer le flux RSS d’un site, même s’il est bien caché !
bsky.rss
bsky.rss est un petit bijou de code qu’on peut trouver ici :
la commande git installée
- hors du champ de ce tuto, mais voici l’essentiel
Docker et Docker-Compose installé
- Installer Docker et Docker-compose
mise en place
Je suis sur Linux Ubuntu, donc l’approche ici part de ce principe :
step 1
- Créer un dossier /bsky-bot/
- Cloner le dépôt à l’intérieur de ce dossier
git clone github.com/milanmdev/bsky.rss disclosengo
- ici “disclosengo” est le nom de votre dossier/bot à vous
step 2
- rentrer dans le dossier via votre terminal
cd disclosengo
structure du dossier
fichier et dossier important
- docker-compose.example.yml
- data/config.example.json
- Dockerfile
ls disclosengo
- Vous devriez voir un dossier data, le fichier compose et le fichier data/config.json
- préparer vos fichiers de config
cp docker-compose.example.yml docker-compose.yml
cp data/config.example.json data/config.json
Mon compose file
Voici à quoi doit ressembler votre fichier docker-compose.yml une fois configuré
version: "3"
services:
bsky-rss:
restart: always # le conteneur se lance au démarrage
image: ghcr.io/milanmdev/bsky.rss
container_name: bsky-rss-disclosengo # le nom du container une fois qu'il tourne
mem_limit: "256m" #mémoire limitée à
mem_reservation: "128m" #mémoire réservée
environment:
- APP_PASSWORD=votre-app-password
- INSTANCE_URL=https://bsky.social
- FETCH_URL=https://disclose.ngo/feed?lang=en
- IDENTIFIER=disclosengo.bsky.social
volumes:
- ./data:/build/data # le fameux dossier data dans le dépôt ? il sera utilisé comme volume d'écriture
Passons sur la branche de test pour bénéficier du système de file d’attente
Prendre la dernière version ici donc à l’heure où j’écris ces lignes c’est : ghcr.io/milanmdev/bsky.rss:queue-4adef77 on va utiliser cette image docker à la place de l’image de base, donc on va remplacer l’entrée image ci dessous.
version: "3"
services:
bsky-rss:
restart: always # le conteneur se lance au démarrage
image: ghcr.io/milanmdev/bsky.rss:queue-4adef77
container_name: bsky-rss-disclosengo # le nom du container une fois qu'il tourne
mem_limit: "256m" #mémoire limitée à
mem_reservation: "128m" #mémoire réservée
environment:
- APP_PASSWORD=votre-app-password
- INSTANCE_URL=https://bsky.social
- FETCH_URL=https://disclose.ngo/feed?lang=en
- IDENTIFIER=disclosengo.bsky.social
volumes:
- ./data:/build/data # le fameux dossier data dans le dépôt ? il sera utilisé comme volume d'écriture
Une fois ce changement fait, il suffit de sauver le fichier après avoir remplis les différents champs de la zone environnement, app password, instance url, fetch url (le rss feed) et l’identifiant.
Si vous utilisez un domaine ça serait par exemple skyfleet.blue au lieu de hande.bsky.social si vous avez besoin de faire tourner plusieurs flux RSS pour le même bot, il suffit de faire la mise ne place ici pour un flux et puis dupliquer tout le répertoire et changer uniquement le flux RSS.
Ma config data/config.sjon
- le lien va être intégré en carte, avec image intégrée grâce à PublishEmbed
- en fonction du flux RSS, la description peut être utilisée pour générer un post plus long que juste le titre
- configurer la langue en fonction du contenu du flux RSS
- truncate c’est pour raccourcir le texte si la description est utilisée
- le runInterval c’est toutes les minutes, il va checker s’il y a du contenu à publier
- le datefield ne vous préoccupez pas avec ça pour le moment
{
"string": "$title", # post le titre
"publishEmbed": true, # créer une carte intégrée en utilisant l'OpenGraph
"languages": ["en"], # la langue de votre flux RSS
"truncate": true, # coupe la description pour ne pas dépasser 300 caractères
"runInterval": 60,
"dateField": ""
}
Options
Quand le “publishEmbed” est en “True”, il n’est pas nécéssaire d’ajouter la variable $link dans le champ string, qui correspond à ce qui va être posté, en effet la génération de la carte Embed, va se baser sur les meta OpenGraph du lien, l’image, la description et le titre qui y sont associés.
{
"string": "$title - $link $description", # en général le titre suffit
"publishEmbed": true, # false déconseillé de mettre en false sauf si pas de lien
"languages": ["en"], # fr, de, es, etc...
"truncate": true, #false
"runInterval": 60, # 120 absent de la branch main
"imageField": "enclosure", # a changer par le nom de votre balise image pour l'imposer au besoin
"ogUserAgent": "", # permet d'imposer un autre user-agent pour se faire passer pour un browser
"forceDescriptionEmbed": "false", # true permet de forcer l'utilisation du champ description du RSS
"descriptionClearHTML": "true", # true va nettoyer le texte de la description de balises html
"dateField": "" # par défaut, il cherche pubDate sauf si le flux RSS n'est pas standard
}
step 3
- à ce stade, vous êtes prêt pour lancer la bête !
Lancement
docker-compose up
D’abord le bot va remplir la file d’attente avec les posts dispo dans le flux RSS
:/home/bsky-bot/disclosengo# docker-compose up
[+] Running 1/1
⠿ Container bsky-rss-disclosengo Created 0.2s
Attaching to bsky-rss-disclosengo
bsky-rss-disclosengo | yarn run v1.22.19
bsky-rss-disclosengo | $ tsx ./app/index.ts
bsky-rss-disclosengo | [Mon, 14 Aug 2023 11:29:24 GMT] - [bsky.rss APP] Started RSS reader. Fetching from https://www.inoreader.com/stream/user/1005343511/tag/Disclosengo every 5 minutes.
[bsky.rss QUEUE] Starting queue handler. Running every 60 seconds
[bsky.rss QUEUE] Queuing item (Revealed: Perenco’s damaging oil spills in Gabon)
[bsky.rss QUEUE] Queuing item (Lützerath: French banks finance the extension of one of Europe’s largest coal mines )
À ce stade, le bot se déploie et vous devriez voir un retour dans votre terminal, si tout va bien, il va checker que le flux RSS et publier ce qu’il trouve à publier, ensuite le bot écrit dans un fichier txt (data/last.txt) la dernière fois qu’il a checker le flux RSS et va utiliser cette date pour comparer s’il y a du nouveau dans le flux RSS et ce toutes les 5 minutes.
[bsky.rss POST] Posting new item (Revealed: Perenco’s damaging oil spills in Gabon)
[bsky.rss POST] Posting new item (Lützerath: French banks finance the extension of one of Europe’s largest coal mines )
[bsky.rss QUEUE] Finished running queue. Next run in 60 seconds
[bsky.rss QUEUE] Running queue with 20 items
[bsky.rss QUEUE] Finished running queue. Next run in 60 seconds
[bsky.rss QUEUE] Running queue with 0 items
Vous pouvez interrompre le bot avec CTRL+C, changer la config, changer le flux RSS, bref fignoler les détails et quand vous êtes content du résultat, vous lancez le bot avec
docker-compose up -d
Cela va lancer le bot comme un processus de tâche de fond.
Repasser sur la branche main, stable du code :
ceci dans le fichier docker-compose.yml
image: ghcr.io/milanmdev/bsky.rss:queue-4adef77
redevient :
image: ghcr.io/milanmdev/bsky.rss
on sauve le fichier et on fait :
docker-compose pull
on vérifie bien que le fichier config.json est bien adapté à la version du code
{
"string": "$title", #vérifier la zone qui va construire le text du post
"publishEmbed": true, #intégration des liens/images
"languages": ["en"], #la,gues
"truncate": true, # couper la description si trop longue
"runInterval": 60, # si pas dans la branche queue
"dateField": "" # champ date spécifique pour flux RSS non-standard
}
Bien faire attention que la dernière ligne de configuration du fichier config.json, ne doit pas comporter de virgule, mais toutes celles qui la précèdent bien !!
On lance la sauce :
docker-compose up -d
vérifier l’état du bot sur laydocker ou docker logs -f nom-de-votre-container
lazydocker
et voilà, vous êtes en train de faire tourner la version stable du bot !
Outils
- J’utilise Lazydocker pour explorer les conteneurs qui tournent, le log, voir si tout va bien
- docker-ctop est aussi pas mal pour explorer vite fait les bots qui tournent
- Il y a moyen de “mixer” plusieurs flux RSS ensemble et ainsi avoir un bot multisources, mais ça, c’est pour un autre tuto !
Bluesky, comment utiliser un newsbot RSS pour générer des Customs Feeds thématiques ?
L’idée avec ce tuto, c’est de démontrer une mise en place d’utilisation des customs feeds sur Bluesky basé sur un News Bot qui va générer le contenu, ce qui va nous permettre de segmenter l’activité du newsbot en différents customs feeds auxquels les utilisateurs vont pouvoir s’abonner.
- D’abord, j’ai été récupérer les Flux RSS de chez LeMonde.fr
- Ensuite, j’ai mis en place un agrégateur de flux afin de rassembler les différents flux d’info par dossier (actu, culture, planète etc..)
- Ensuite, j’ai mis en place le newsbot en tant que tel en suivant mon tuto
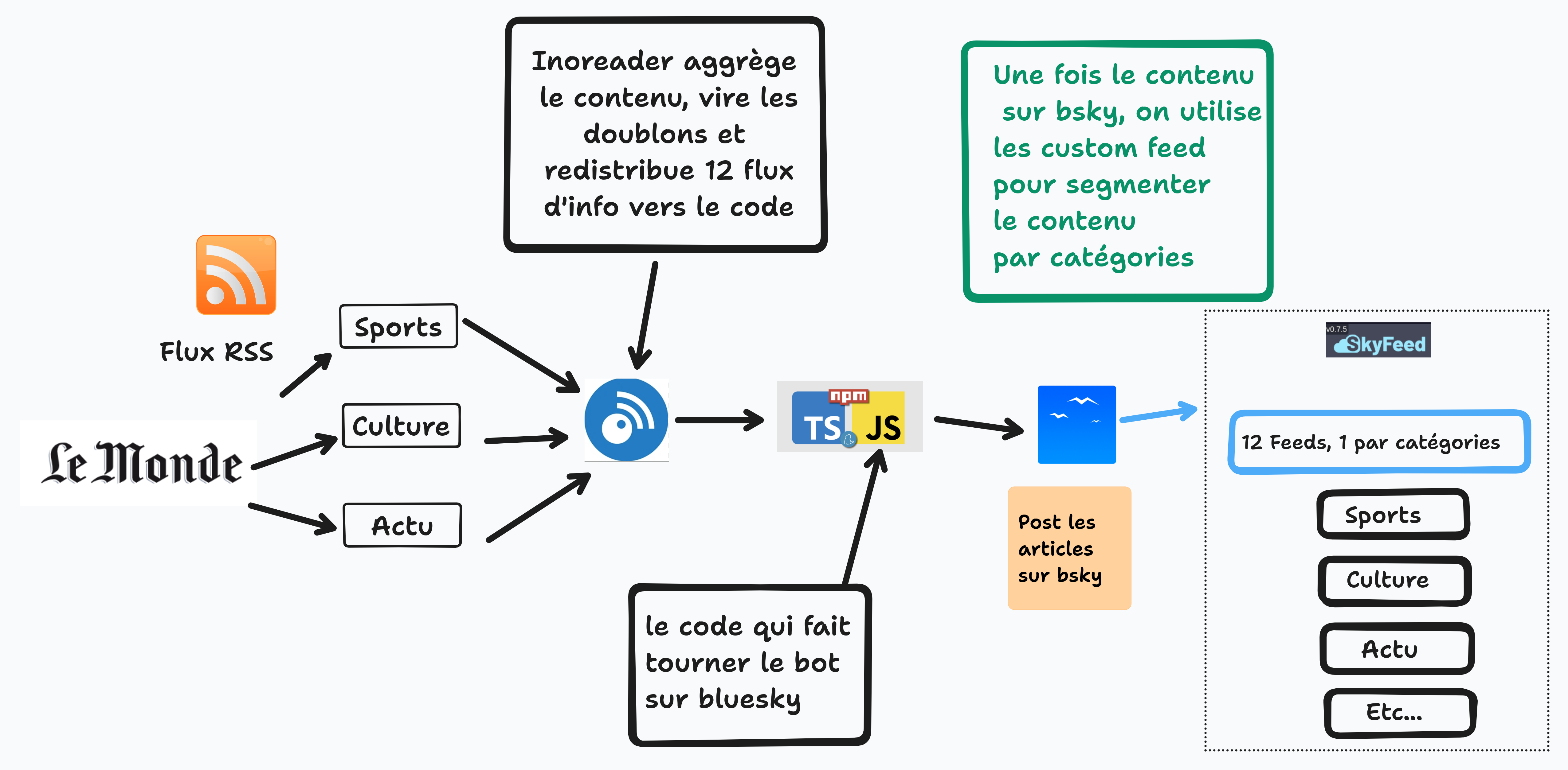
12 flux de veilles sur un même compte bluesky

Il y a donc 12 processus de veille RSS qui tournent, un par catégorie maitresse sur le site LeMonde

Comment sont construits les custom feeds ?
J’avais besoin d’une ancre stable sur lequel me baser pour chaque catégorie et je ne pouvais pas prévoir tous les mots utilisés dans un titre ou la description pour segmenter les articles en différent flux thématique, du coup, en éditant mon fichier config.json, je peux segmenter avant même la publication, et ce, de manière stable :
config.json pour Actu
{
"string": "Actu: $title",
"publishEmbed": true,
"languages": ["fr"],
"truncate": true,
"runInterval": 60,
"dateField": ""
}
config.json pour Culture
{
"string": "Culture: $title",
"publishEmbed": true,
"languages": ["fr"],
"truncate": true,
"runInterval": 60,
"dateField": ""
}
Etc.. etc..ce qui me permet de prendre le dossier/catégorie culture, actu, sports, france etc… et d’avoir une segmentation simple sans devoir passer par des tas de requête regex qui ne donneraient pas une segmentation aussi simple et efficace.
Résultat de la veille sur Bluesky

Skyfeed custom feed builder
Vue de la mise en place d’un custom feed avec skyfeed.app

Listes des custom feeds sur @lfm.bsky.social

Résultats :

le problème des doublons (résolu)
Pour régler les problèmes de doublons, c’est-à-dire, un article qui apparaît dans 2 ou 3 flux, j’ai déjà viré les flux à la Une, vu qu’ils reprennent le contenu des catégories, ensuite grâce à Inoreader, je vire les doublons d’une même catégorie en faisant un tri sur les articles qui ont le même titre, mais qui sont publiées à plusieurs endroits et enfin, on utilise le flux de sortir du dossier (culture, actu, sports etc..) comme input d’entrée du bot qui veille à l’arrivée de nouvelles publications et qui s’en charge de les publier.
Modification par la suite de la première version de ce tuto :
Vu qu’il y avait encore des doublons, tout a été reconstruit, c’est à dire que l’agrégation de l’ensemble des flux cités ci plus haut sont rassemblé dans un seul dossier, sur lequel le check de duplicatas se fait, ainsi ça vire les doublons d’une manière transversale, sur l’ensemble de la veille.
Ensuite pour faire la segmentation, au lieu de la faire sur des préfix qui annonce de quel catégorie vient l’article, on se base sur la structure des articles chez LeMonde pour segmenter l’information en plusieurs custom feeds : dont /internatonal/ ou /economie/ ou /culture/ dans l’URL deviennent les repères sur lesquels se fait la segmentation, résultat, plus de doublons et des customs feeds par catégories;
Tout de même certain choix ont dû être fait, par exemple la catégorie Idées du journal ont été mise dans le segment Actualités.
Comment segmenter l'activité d'un compte sur bluesky par langue ?
Je n’ai pas encore fait des customs feeds segmenté par langues sur mes news bots bilingues, mais imaginons que vous avez envie de vous farcir @Sciences mais qu’en français pour l’exercice de ce tuto !
La recette est plutôt simple, voici les ingrédients :
- Un App Password que vous générez dans les paramètres de votre compte pour vous connecter sur @skyfeeds.app
- le DID du compte que vous voulez segmenter
- mon révélateur de DID
- Rendez-vous ici DID
- Tapez siences.bsky.social dans le premier champ
- vous obtenez ceci : did:plc:56p5hqta5tnz25tucrnszplh
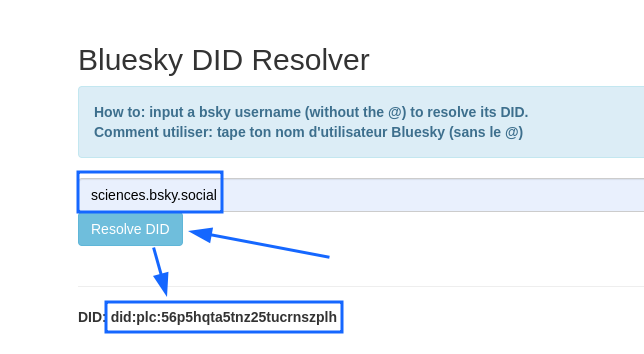
Étape Skyfeed.app
- Rendez-vous sur @skyfeeds.app
- Connectez-vous avec votre App Password, ce mot de passe alternatif généré sur votre compte perso
Suivre ces étapes pour segmenter l’activité d’un compte bilingue sur une langue
5.1 On clique sur “feed builder” à gauche, puis sur créer un Feed dans le haut de la colonne qui s’ouvre
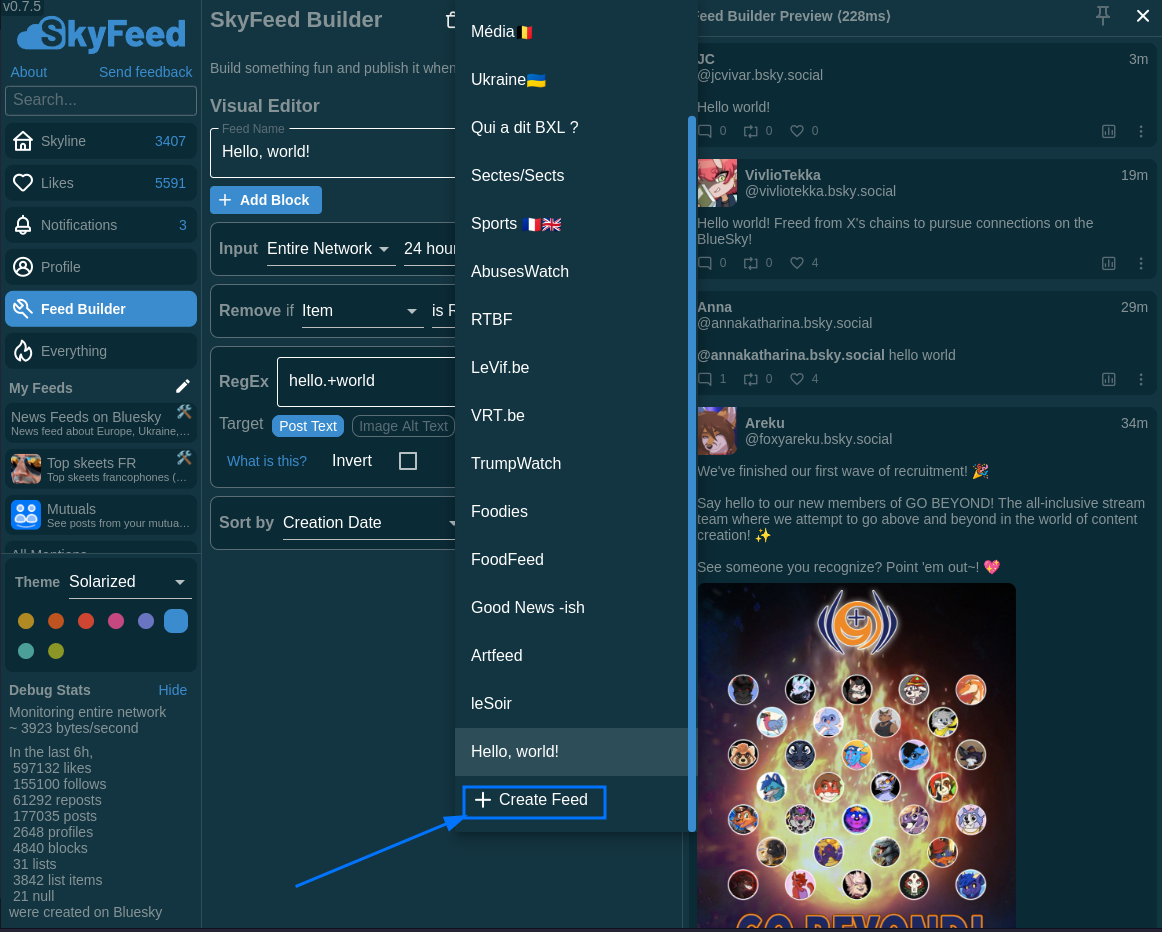
5.2 vous vous retrouvez avec un exemple “Hello World' on va déjà nettoyer tout ce qu’on n’en veut pas
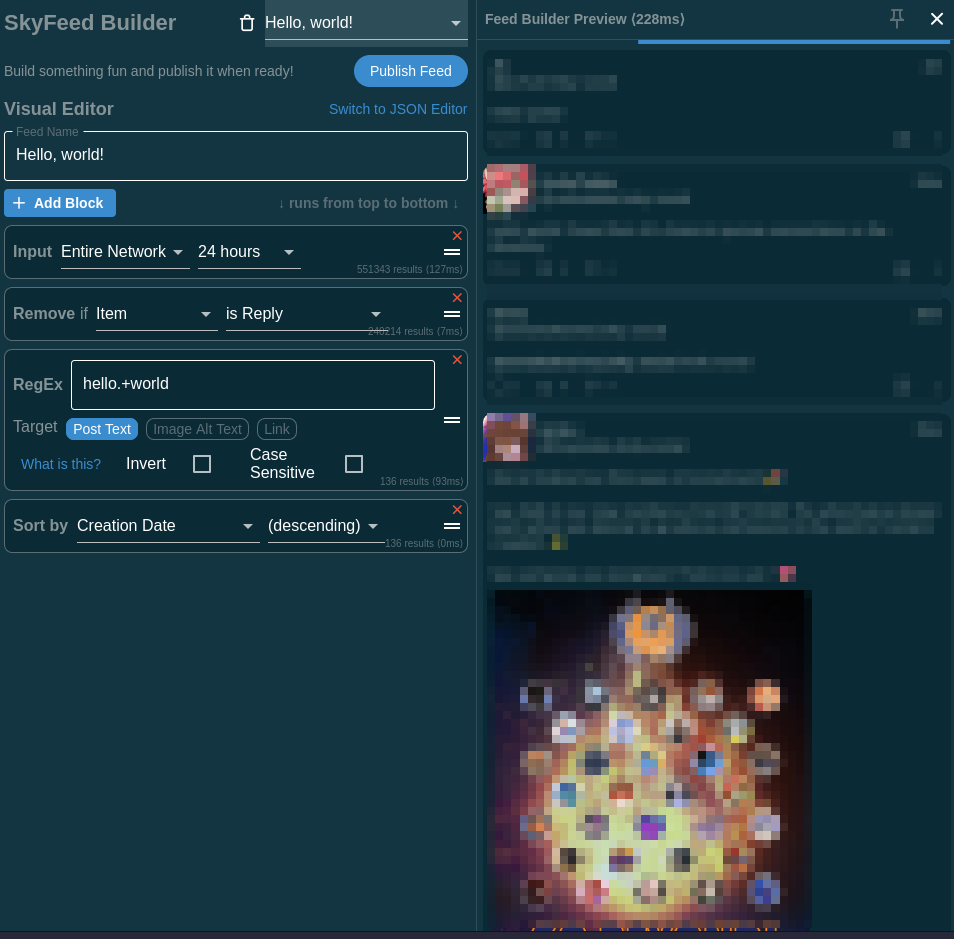
5.3 On donne un titre et on ne garde que les blocs en clair, dans l’input, on choisit Single User : on colle l’identifiant did:plc:56p5hqta5tnz25tucrnszplh du compte Sciences récupéré au début du tuto.
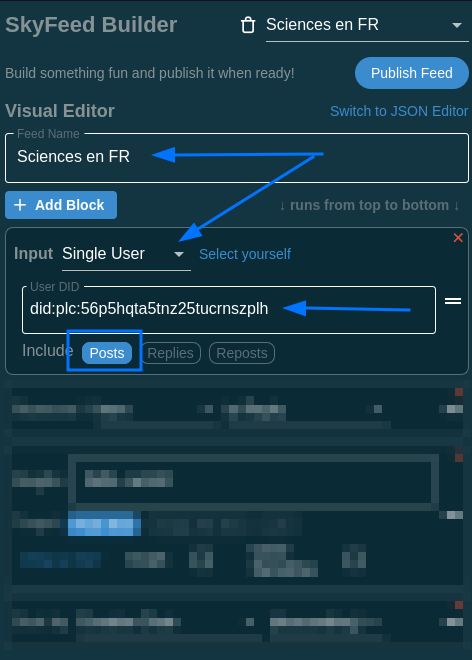
5.4 on se retrouve avec ceci :
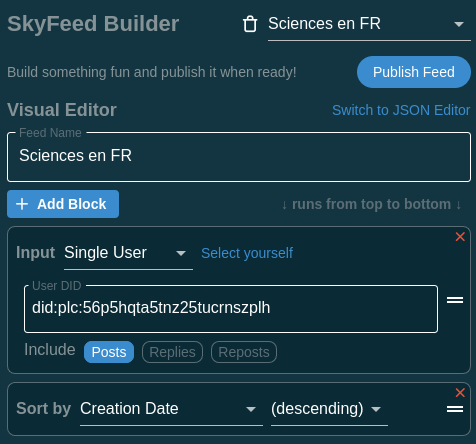
5.5 à cette étape, les posts affiché sont toujours en deux langues, on va s’occuper de ça.
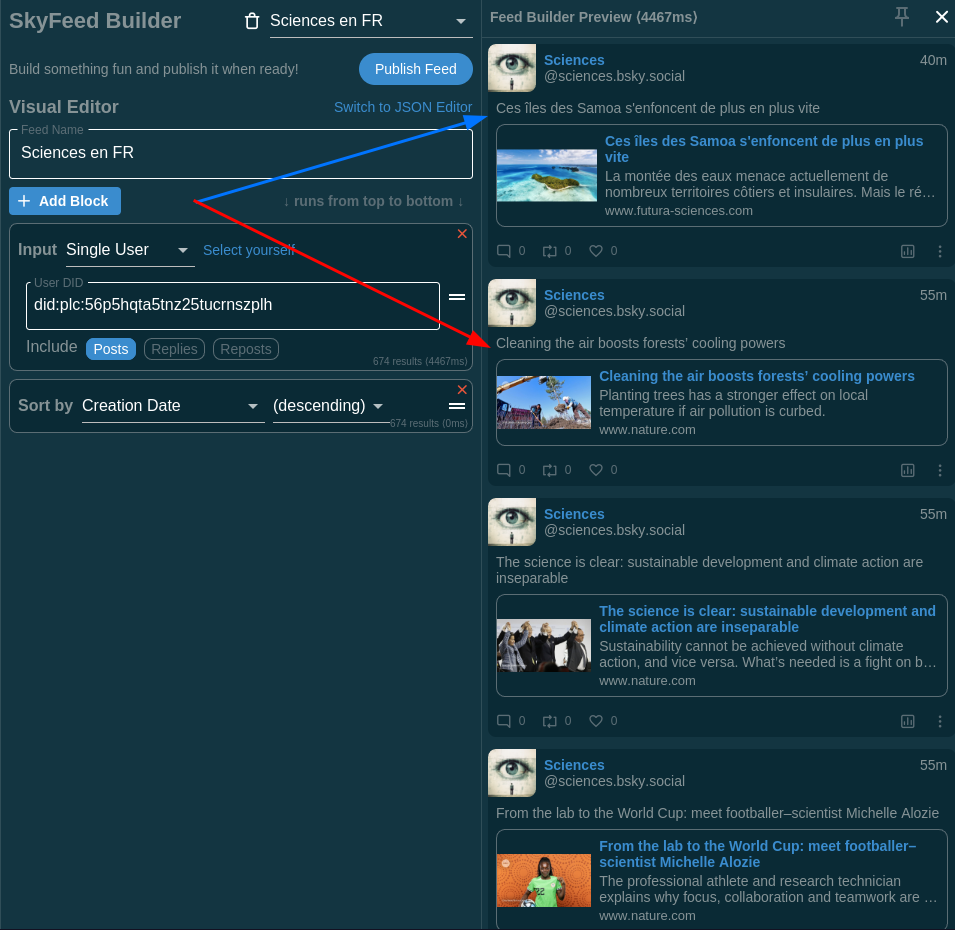
5.6 On va rajouter un Block et comme Input, on va choisir Remove
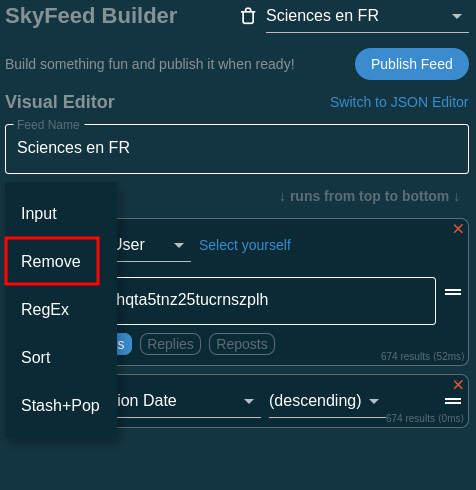
5.7 là, on va choisir Language dans la liste déroulante du block remove
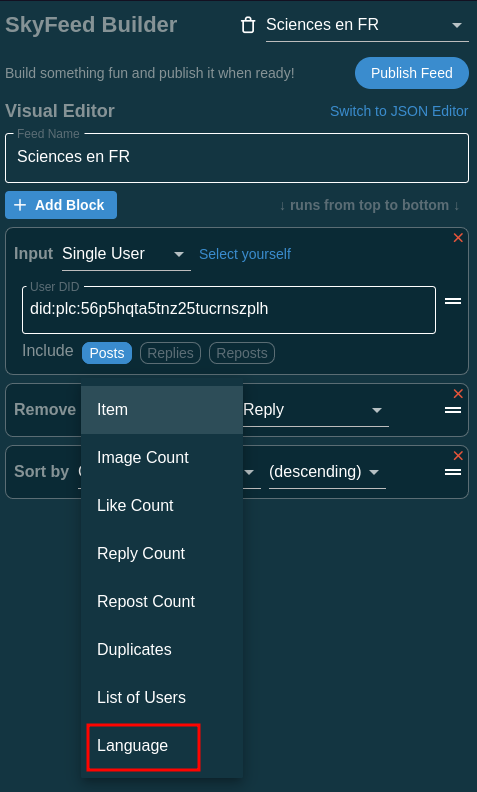
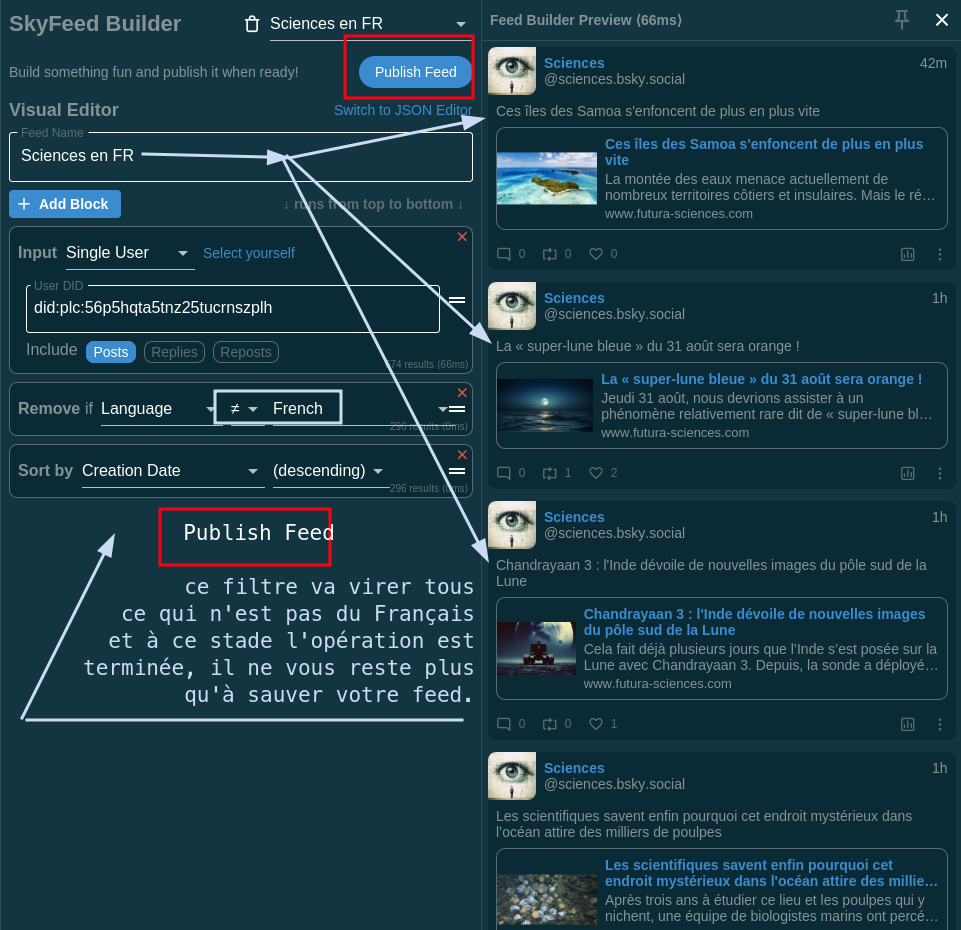
5.8 à ce stade, c’est quasi terminé, on choisit French et le petit = barré pour dire, tout ce qui n’est pas égal à du français, on le vire du flux.
À ce moment-là, le contenu sur la colonne de preview à droite n’affiche que des posts en français. On peut sauver notre Feed à ce stade en le publiant.
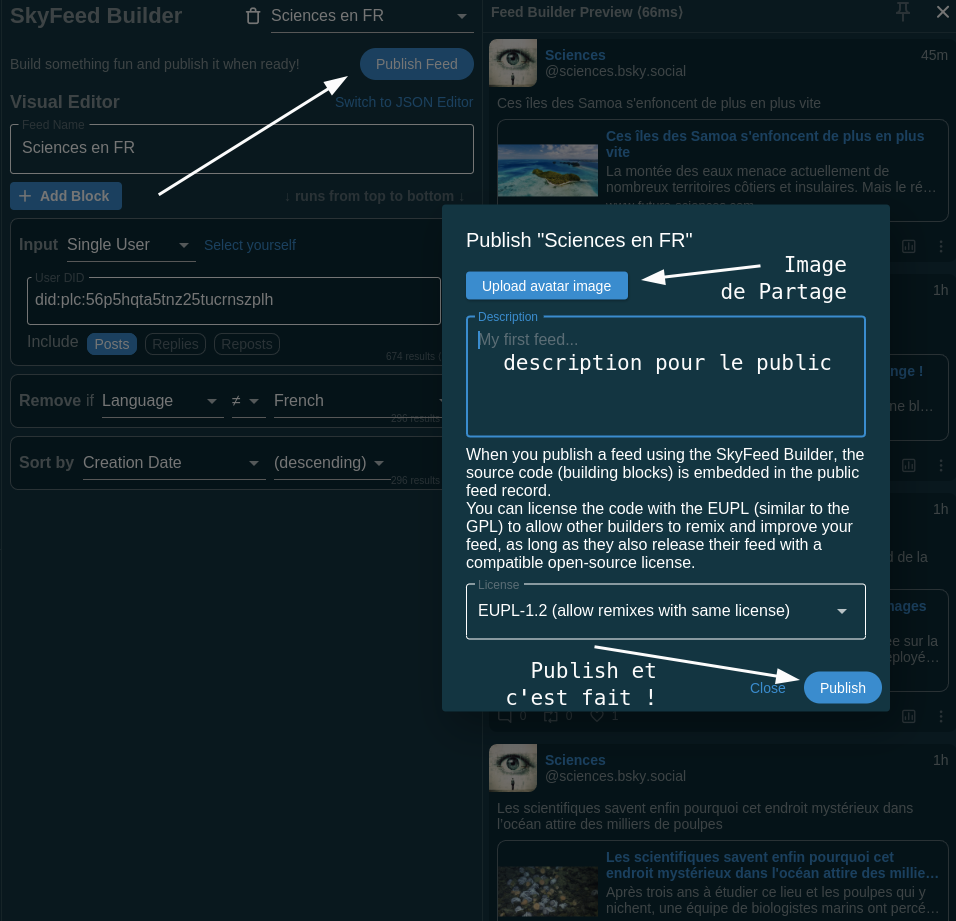
5.9 Ici, on remplit les champs et éventuellement ajoute une image qui sera visible pour les utilisateurs ou au moment du partage du custom feed
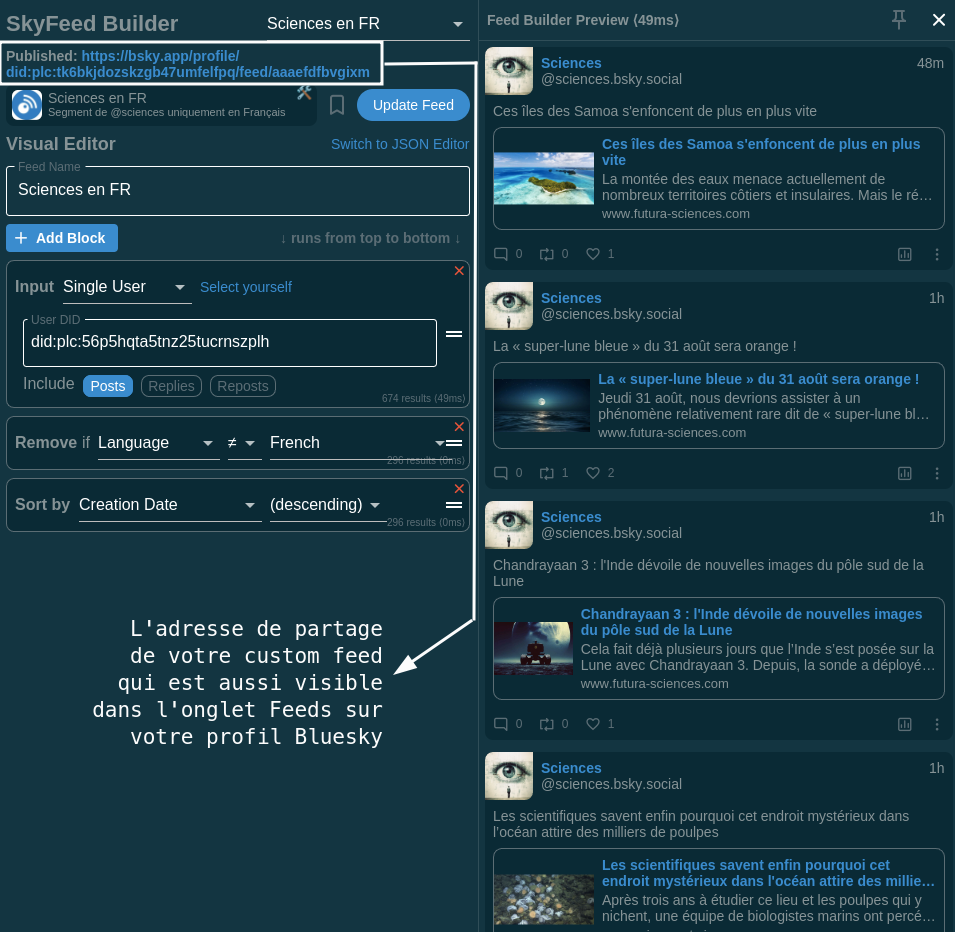
6.0 Ici, vous avez dans l’encadré supérieur l’adresse de votre Custom Feed, c’est avec ce lien que vous pouvez le partager à d’autres personnes sur le réseau.
Résultats
- Voici le Custom Feed en question
Ceci est juste un exemple de ce qui peut être fait en termes de custom feed sur un compte, vous pourriez bien rajouter un champ regex en mentionnant uniquement vouloir recevoir des actus sur Mars ou sur le James Webb Telescope, ou uniquement les posts contenant 10 likes etc…
-
Ce custom feed peut être actualisé en éditant simplement le feed et en republiant ce dernier les changements sont immédiats.
-
L’avantage des customs feeds sur lesquels vous avez la main, c’est que vous pouvez les changer les améliorer etc..contrairement au custom feed sur le compte des autres.
Conseils
- Si vous ne voyez pas une langue sur Bluesky, c’est qu’il faut aller dans les préférences de votre compte perso et définir que vous voulez bien voir X ou Y langues sur bluesky, autrement, vous ne voyez tout simplement pas les langues qui ne sont pas activées.
Ex: @EUwatch est tri lingues, mais si vous n’avez pas l’espagnol, et l’anglais activé sur votre compte, vous ne verrez que l’actualité en Français sur ce compte.
L’avantage d’un custom feed segmenté, c’est que vous pouvez ne pas suivre le compte si le volume est trop important et recevoir uniquement ce qui vous intéresse, que ce soit par choix de langue ou mots clefs.